实用化 AI 算力又升上了一个新台阶。
随着AI大模型加速迭代,智能算力已成为稀缺资源。算力是AI发展的底层土壤,大语言模型的训练和推理都需要消耗大量的计算资源。传统的通用算力往往难以满足大模型对算力的高需求,因此,强大可靠的AI算力底座显得尤为重要。
一些让人始料未及的趋势在人工智能的应用领域出现了:很多传统企业开始选择在CPU平台上落地和优化AI应用。
例如制造领域在高度精细且较为耗时的瑕疵检测环节,就导入了CPU及其他产品组合,来构建横跨“云-边-端”的AI 缺陷检测方案,代替传统的人工瑕疵检测方式。
再比如亚信科技就在自家OCR-AIRPA方案中采用了CPU作为硬件平台,实现了从FP32到INT8/BF16的量化,从而在可接受的精度损失下,增加吞吐量并加速推理。将人工成本降至原来的1/5到1/9,效率还提升了约5-10倍。
在处理AI制药领域最重要的算法——AlphaFold2这类大型模型上,CPU同样也“加入群聊”。从去年开始,CPU便使AlphaFold2端到端的通量提升到了原来的23.11倍;而现如今,CPU让这个数值再次提升3.02倍。
上述这些CPU,都有个共同的名字——至强,即英特尔®️ 至强®️ 可扩展处理器。
为什么这些AI任务的推理能用CPU,而不是只考虑由GPU或AI加速器来处理?
这里历来存在很多争论。
很多人认为,真正落地的AI应用往往与企业的核心业务紧密关联,在要求推理性能的同时,也需要关联到它的核心数据,因此对数据安全和隐私的要求也很高,因此也更偏向本地化部署。
而结合这个需求,再考虑到真正用AI的传统行业更熟悉、更了解也更容易获取和使用CPU,那么使用服务器CPU混合精度实现的推理吞吐量,就是他们能够更快和以更低成本解决自身需求的方法了。
面对越来越多传统AI应用和大模型在CPU上的落地优化,“用CPU加速AI”这条道路被不断验证。这就是在数据中心中,有70%的推理运行在英特尔® 至强® 可扩展处理器上的原因。1
最近,英特尔的服务器CPU完成了又一次进化。12月15日,第五代英特尔® 至强® 可扩展处理器正式发布。英特尔表示,一款为AI加速而生,而且表现更强的处理器诞生了。

人工智能正在推动人类与技术交互方式的根本性转变,这场转变的中心就是算力。
英特尔CEO帕特·基辛格(Pat Gelsinger)在2023英特尔ON技术创新大会表示:“在这个人工智能技术与产业数字化转型飞速发展的时代,英特尔保持高度的责任心,助力开发者,让AI技术无处不在,让AI更易触达、更可见、透明并且值得信任。”
第五代至强 为AI加速
第五代英特尔® 至强® 可扩展处理器的核心数量增加至64个,配备了高达320MB的L3缓存和128MB的L2缓存。不论单核性能还是核心数量,它相比以往的至强都有了明显提升。在最终性能指标上,与上代产品相比,在相同功耗下平均性能提升21%,内存带宽提升高达16%,三级缓存容量提升到了原来的近3倍。

更为重要的是,第五代至强® 可扩展处理器的每个内核均具备AI加速功能,完全有能力处理要求严苛的AI工作负载。与上代相比,其训练性能提升多达29%,推理能力提升高达42%。
在重要的AI负载处理能力上,第五代英特尔® 至强® 可扩展处理器也交出了令人满意的答卷。
首先要让CPU学会高效处理AI负载的方法:在第四代至强® 可扩展处理器上,英特尔面向深度学习任务带来了矩阵化的算力支持。
英特尔®️ AMX就是至强CPU上的专用矩阵计算单元,可被视为CPU上的Tensor Core,从第四代至强® 可扩展处理器开始成为内置于CPU的AI加速引擎。
第五代至强®️ 可扩展处理器利用英特尔®️ AMX与英特尔®️ AVX-512指令集,配合更快的内核,以及速度更快的内存,可以让生成式AI更快地在其上运行,无需独立的AI加速器就能执行更多工作负载。
借助在自然语言处理 (NLP) 推理方面实现的性能飞跃,这款全新的至强® 可支持响应更迅速的智能助手、聊天机器人、预测性文本、语言翻译等工作负载,可以在运行参数量200亿的大语言模型时,做到时延不超过100毫秒。
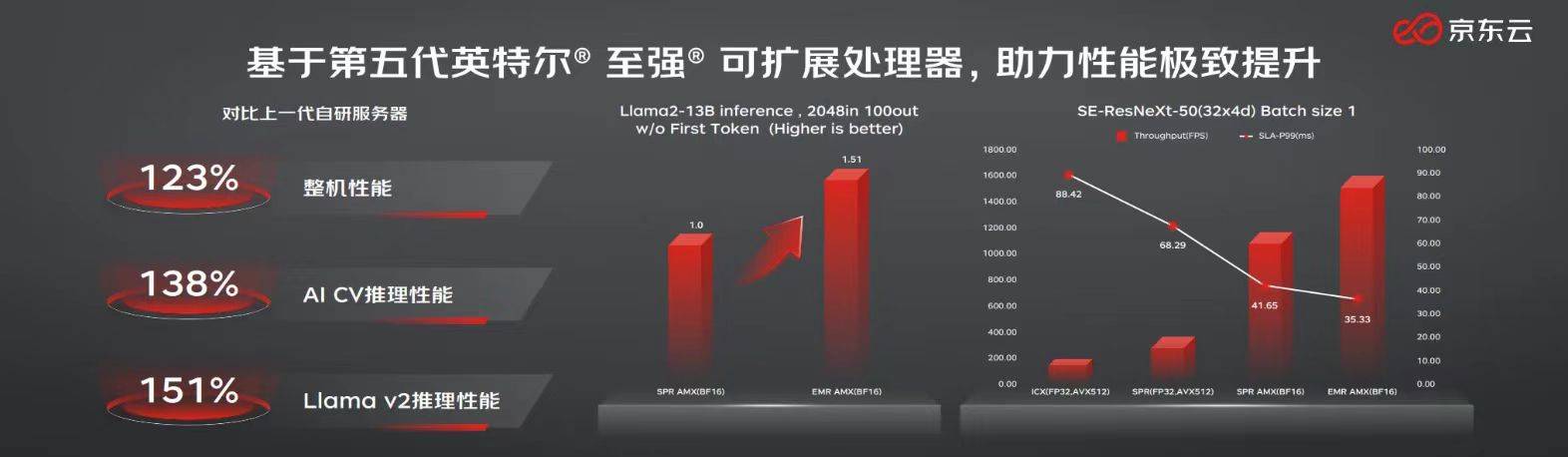
据了解,11.11期间,京东云便通过基于第五代英特尔® 至强® 可扩展处理器的新一代服务器,成功应对了业务量激增。与上一代服务器相比,新一代京东云服务器实现了23%的整机性能提升,AI计算机视觉推理性能提升了38%,Llama v2推理性能也提高了51%,轻松hold住用户访问峰值同比提高170%、智能客服咨询量超14亿次的大促压力。
除此之外,第五代英特尔® 至强® 可扩展处理器也在能效、运营效率、安全及质量等方面实现了全面提升,提供了向前代产品的软件和引脚兼容性支持,以及硬件级安全功能和可信服务。
国内云服务大厂阿里云也在发布会上披露了其实测体验数据,基于第五代英特尔® 至强® 可扩展处理器及英特尔® AMX、英特尔® TDX加速引擎,阿里云打造了 “生成式AI模型及数据保护”的创新实践,使第八代ECS实例在实现了全场景加速和全能力提升情况下,更加固了安全性能,且保持实例价格不变,普惠客户。
数据显示,其在数据全流程保护的基础上,AI推理性能提高25%、QAT加解密性能提升20%、数据库性能提升25%,以及音视频性能提升15%。

英特尔表示,第五代至强® 可扩展处理器可为AI、数据库、网络和科学计算工作负载带来更强大的性能和更低的TCO,将目标工作负载的每瓦性能提升高达10倍。
对先进AI模型实现原生加速
为让CPU能够高效处理AI任务,英特尔把AI加速的能力提升到了「开箱即用」的程度。
英特尔®️ AMX除了可以加速深度学习的推理、训练以外,现在已经支持了流行的深度学习框架。在深度学习开发者常用的TensorFlow、PyTorch上,英特尔® oneAPI深度神经网络库 (oneDNN) 提供了指令集层面的支持,使开发人员能够在不同硬件架构和供应商之间自由迁移代码,可以更轻松地利用芯片内置的AI加速能力。
在保证了AI加速直接可用之后,英特尔利用高性能开源深度学习框架OpenVINO™ 工具套件,帮助开发者实现了一次开发、多平台部署。它可以转换和优化使用热门框架训练好的模型,在多种英特尔硬件的环境中快速实现,帮用户最大程度地利用已有资源。
OpenVINO™ 工具套件最新的版本也加入了对大型语言模型 (LLM) 性能的改进,可以支持生成式AI工作负载,包括聊天机器人、智能助手、代码生成模型等。
OpenVINO™ 工具套件2
通过这一系列技术,英特尔让开发者们能够在几分钟内调优深度学习模型,或完成对中小型深度学习模型的训练,在不增加硬件和系统复杂性的前提下获得媲美独立AI加速器的性能。
比如在先进的预训练大语言模型上,英特尔的技术就可以帮助用户完成快速部署。
用户可以从最热门的机器学习代码库Hugging Face中下载预训练模型LLaMA2,然后使用英特尔®️ PyTorch、英特尔®️ Neural Compressor等将模型转换为BF16或INT8精度版本以降低延迟,再使用PyTorch进行部署。
英特尔表示,为了能够紧跟AI领域的潮流,有数百名软件开发人员正在不断改进常用的模型加速能力,让用户能够在跟上最新软件版本的同时,获得对于先进AI模型的支持。
第五代至强® 可扩展处理器的实力,目前已在部分大厂进行了验证。火山引擎与英特尔合作升级了第三代弹性计算实例。
目前,火山引擎已通过独有的潮汐资源并池能力,构建百万核弹性资源池,能够以近似包月的成本提供按量使用体验,降低上云成本。基于第五代英特尔® 至强® 可扩展处理器,火山引擎第三代弹性计算实例整机算力再次提升了39%,应用性能最高提升了43%。

这只是个开始。可以预见,很快会有更多科技公司的应用能够从第五代至强®️ 可扩展处理器的性能中获益。
下一代至强已经现身
未来,人们对于生成式AI的需求还将不断扩大,更多的智能化应用将会改变我们的生活。以计算能力为基础,万物感知、万物互联、万物智能的时代正在加速到来。
面对这样的趋势,英特尔正在加紧打造再下一代的至强CPU,它们面向AI的「专业化」程度还会更高。
在最近披露的英特尔数据中心路线图上,下一代至强® 处理器将对不同工作负载、场景配备不同的核心,其中主打计算密集型与AI任务的型号会使用侧重性能输出的核「P-core」,面向高密度与横向扩展负载的型号则会使用有更高能效的核「E-core」,这两种不同的核心架构并存的设计,既满足部分用户对极致性能的追求,也能兼顾到可持续发展绿色节能的需求。
未来,英特尔还将如何实现晶体管和芯片性能的飞跃,在AI算力上还能有什么样的跃升?
让我们拭目以待。

关键词:
责任编辑:Rex_22